Matthew Sun
Hi there! I'm a second-year graduate student at Princeton advised by Arvind Narayanan. Previously, I double majored in Computer Science and Public Policy at Stanford University. I'm interested in fairness in machine learning and computing for social good as well as algorithmic bias, discrimination, and systemic harm. At Stanford, I led CS+Social Good, did research through the Stanford Machine Learning Group, Partnership for AI-Assisted Care, and the Stanford Network Analysis Project, and am a peer counselor at the Bridge Peer Counseling Center.
I'm interested in applying a Rawlsian notion of justice to algorithmic fairness: how should society distribute the social benefits and costs of algorithmic decisionmaking?
Feel free to check out my personal homepage!
mdsun [at] princeton.edu
Projects

The Scales of (Algorithmic) Justice: Tradeoffs and Remedies
Marissa Gerchick*, Matthew Sun*
Winner of the 2018 ACM Special Interest Group on Artifical Intelligence Student Essay Contest.
Summary: In this paper, we explore the viability of potential legal challenges to the use of algorithmic decision-making tools by the government or federally funded agencies. First, we explore the use of risk assessments at the pre-trial stage in the American criminal justice system through the lens of equal protection law. Next, we explore the various requirements to mounta valid discrimination claim — and the ways in which the use of an algorithm might complicate those requirements — under Title VI of the Civil Rights Act of 1964. Finally, we suggest the adoption of policies and guidelines that may help these governmental and federally funded agencies mitigate the legal (and related social) concerns associated with using algorithms to aid decision-making. These policies draw on recent lawsuits relating to algorithms and policies enacted in the EU by the General Data Protection Regulation (GDPR).

CS+Social Good: Building a Curricular Ecosystem of Tech for Impact at Stanford and Beyond
Belce Dogru*, Vik Pattabi*, Matthew Sun*
Accepted at the Computing for the Social Good in Computer Science Education Workshop at the ACM Special Interest Group on Computing and Society CSG-Ed Mini-Symposium '19; invited for presentation on panel.
Summary: This submission introduces CS+Social Good, a student organization at Stanford University which works at the intersection of tech and social impact. In this paper, we spotlight one of our educational initiatives that might be of interest to the SIGCSE community, focusing specifically on our Studio program, which is offered as CS51 and CS52 at the Stanford University Computer Science Department. For this student-taught class, student teams partner with nonprofits and social ventures to build impactful technical projects over the course of two quarters. We also discuss other classes and initiatives that have built an ecosystem of tech for good programming at Stanford.
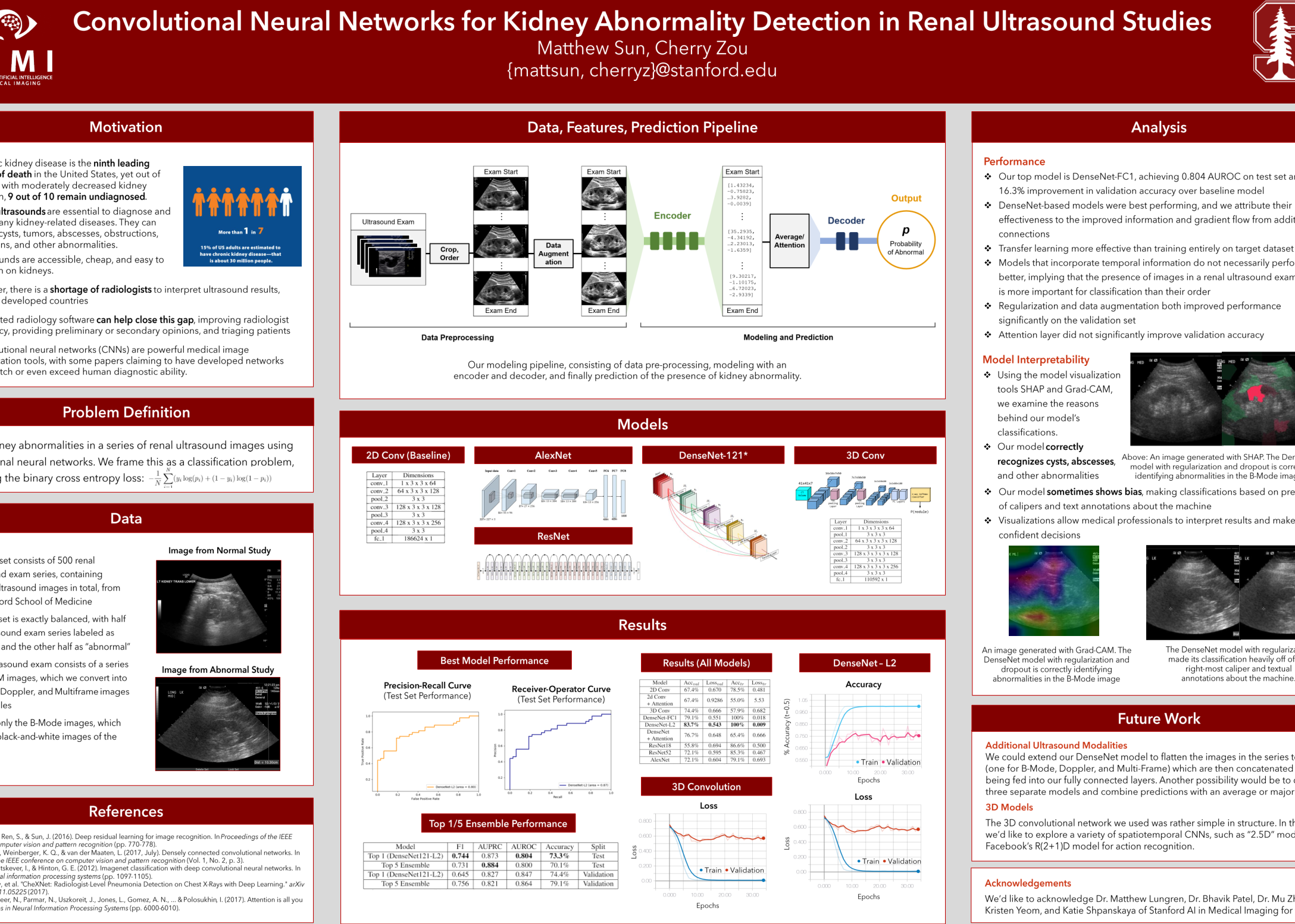
Convolutional Neural Networks for Kidney Abnormality Detection in Renal Ultrasound Studies
Matthew Sun*, Cherry Zou*, Mu Zhou, Matthew Lungren, Bhavik Patel, Katie Shpanskaya, Kristen Yeom
Summary: Kidney failure is the ninth leading cause of death in the United States, yet 90 percent of kidneys with moderately decreased function remain undiagnosed, largely due to a shortage of radiologists worldwide. Renal ultrasounds are the most accessible, inexpensive, and informative diagnostic tool for many kidney-related diseases, making ultrasounds ideal for automated detection and diagnosis. Convolutional neural networks (CNNs) demonstrate great efficacy on medical image classification tasks, but little research targets the ultrasound modality. To address this need, we present an algorithm to detect abnormal renal ultrasound studies. Our algorithm is a 121-layer densely-connected CNN trained on 20,000 renal ultrasound exams. Our deep learning algorithm achieves 0.804 AUROC. To maximize clinical relevance, we also address model bias and interpretability.
A Student-Teacher RL Algorithm for Neural Program Synthesis with VisualFeedback
Jonathan Booher*, Matthew Sun*
Summary: Neural code synthesis has proven an extremely difficult task for computers to learn, even with hand-crafted objective functions. Solutions tend to be narrowly tailored, and often exhibit a tradeoff between computer performanceand human readability. We aim to approach the problem of neural code synthesis through visual programming, ahuman-readable form of computer programming. Visual programming is a popular way to introduce computer science students to foundational programming concepts. We demonstrate that a reinforcement learning algorithm is able to efficiently learn visual programming tasks via a “curriculum” of increasing difficulty, similar to how human students might learn computer science. In particular, we note that as the agent progresses through the curriculum, it is able to achieve the current task relatively quickly through few-shot learning, indicating that it leverages the concepts learned in prior tasks.

Comparing Privacy-Preserving Methods for Action Recognition in Smart Hospitals
Edward Chou, George He*, Anirudh Jain*, Matthew Sun*, Matthew Tan*
Summary: Hospitals that utilize computer vision and machine intelligence techniques have the potential to improve patient treatment and outcomes. However, the implementation of these systems is often met with resistance due to the perceived intrusiveness and violation of privacy associated with visual surveillance. In this paper, we explore three distinct methods for preserving patient privacy. We implement our techniques within the contextof an actual healthcare-surveillance scenario, hand-hygiene compliance, and show that our privacy-preserving techniques add additional privacy guarantees while preserving enough information for action recognition in a realistic action-rich healthcare environment.

@Bots or @Potts? Classifying Tweets as Human-Written or Machine-Written
Laura Cruz-Albrecht*, Kevin Khieu*, Matthew Sun*
Summary: According to a study by Pew Research Center in April 2018, 66% of tweeted links to popular websites on Twitter are now generated by bots. With the recent rise of bot generated content, effectively identifying whether text is human or machine-generated is now more important than ever. This project is aimed at studying the problem of classifying tweets as either human-written or machine-written. Specifically, this project experiments with the effectiveness of different feature extraction methods plus the performance of Support Vector Machines, Logistic Regression, and Recurrent Neural Networks.
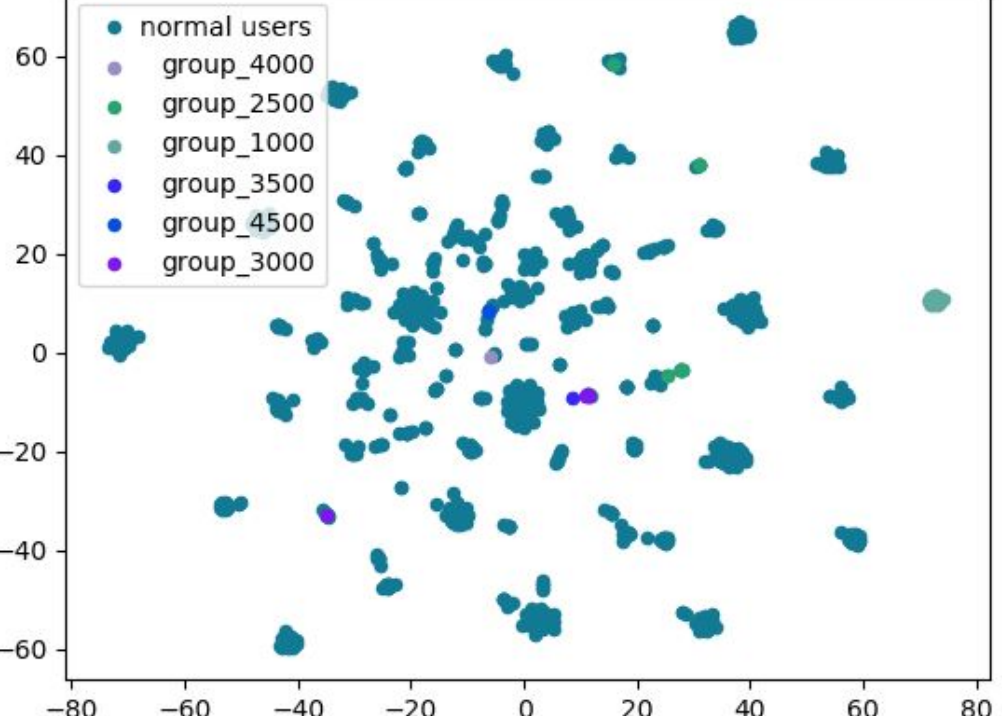
Sockpuppet Account Detection on Reddit with Deep Learning
Matthew Sun, advised by Srijan Kumar and Jure Leskovec
Summary: Deceptive behavior online has emerged in the mainstream discourse as an increasingly important issue to address. From false advertising to fake news, deception online has become a serious threat to individual users, marginalized groups, and even national defense. In this project, we seek to tackle two problems: (1) Given a particular Reddit user, can we reliably predict whether that user is a sockpuppet master, and(2) Given any two Reddit users, can we identify whether they are part of the same sockpuppet group (i.e., controlled by the same user)? My focus this quarter was to apply both traditional graph representation learning techniques as well as novel deep learning models to both of these classification tasks, to better understand the performance of deep learning methods as compared to traditional baselines.
* denotes alphabetical order.